Hi! I’m sorry no easy answer here.
Here is a document I created with a few approaches: https://public.getgrist.com/5uak5drY3QD3/Extract-Domain/m/fork
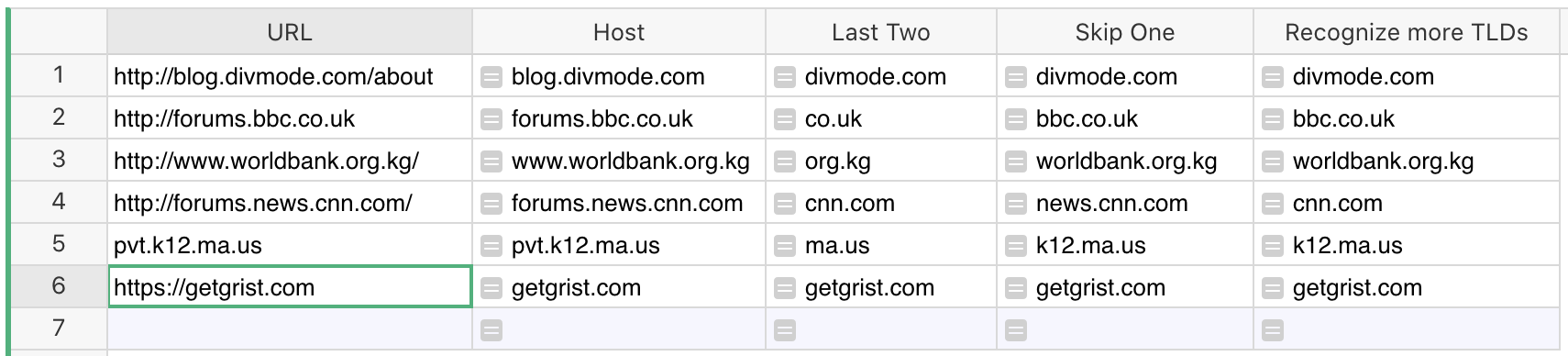
Getting the host from URL is straightforward (I am using an import style that will work unchanged with Python2 and Python3 – because of the upcoming Python3 project):
from six.moves.urllib.parse import urlparse
urlparse($URL).hostname
To handle either valid URLs or plain hostnames, you can add:
urlparse($URL).hostname if "/" in $URL else $URL
To extract the last two dot-separated parts of a host, this can be used:
".".join($Host.split(".")[-2:])
Another simplistic approach is in the “Skip One” column – useful if you expect to skip one subdomain part normally, and that’s all.
But if you are using the tldextract library, you probably care about the multi-part TLDs, like co.uk. There are surprisingly many of those, and there is no pattern. It’s impossible to replicate the full functionality of tldextract without storing that full list somewhere, but you can have a partial solution that will work for many common cases.
The last column in the document is of the type you mention (regex):
re.sub(r'^.*?(\w+\.(\w+|(co|com|org)\.\w\w|\w\w\.us))$', r"\1", $Host)
It allows adding more special handling to the regular expression to capture other likely cases of multi-part TLDs. As you say, it’s imperfect and complicated, but hopefully useful if it gets the job done.