How can I make Grist automatically add every entry from column ‘A’ to column ‘B’? The goal is make column ‘B’ to serve as a history of column ‘A’, showing all changes made to column ‘A’ from the beginning
In the column ‘B’, set the following Trigger Formula:
import datetime
current_time = NOW().strftime(“%Y-%m-%d %H:%M:%S”)
new_entry = f"{current_time}: { $COLUMN_A }"
return (value + "\n" + new_entry) if value else new_entry
- Note that in the line new_entry = f"{current_time}: { $COLUMN_A }" you will need to change “COLUMN_A” for the name of the real column
Then, check the option “Apply on changes to:” and then select the column ‘A’
DONE!
This is the explanation of the code:
- “NOW().strftime(“%Y-%m-%d %H:%M:%S”)”: gets the current date and time in the format “YYYY-MM-DD HH:MM”
- new_entry: create a new line that includes the date-time and the current value of the ‘A’ column.
- value: refers to the existing value in the column ‘B’. The formula appends the new entry to this existing value, creating a new line each time.
- \n: Represents a newline character, ensuring each change is recorded on a new line.
I would like to give credit for this tip to my friend @Rogerio_Penna. Thank you so much!
5 Likes
You are welcome.
At Discord you asked: “do you know if is there any way to make the second column keep its regular height?”
I don´t think so. Grist yet does not allows you to set maximum number of rows for text fields.
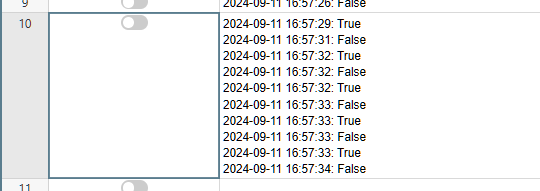
One problem of the method above, if column A is a text field, is that the formula will record EVERYTHING that was written in the cell.\
do if you have a long text with multiple rows, and change a single character, the ENTIRE text will be copied to Column B twice, with that single character changed.
Thus, it must be used carefully to avoid dozens of huge texts being copied on each row of column B.
Preferentially, it should be used on other types of columns (options, references, numbers, dates, etc)
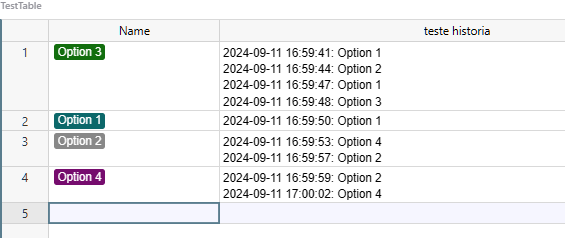
1 Like
damn, my Grist clock is wrong. It’s 14:00 now
weird… the time zone is correct
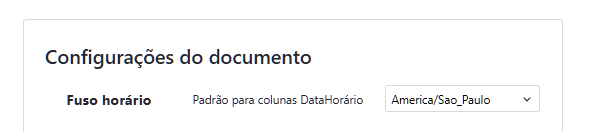
there is something wrong in my formula. The timestamp in the next column is getting the time correctly

fixed formula, getting the correct TIME ZONE
current_time = NOW().strftime(“%Y-%m-%d %H:%M:%S”)
new_entry = f"{current_time}: { $Name }"
return (value + “\n” + new_entry) if value else new_entry
2 Likes
You are right! I’ve just changed the Solution with this new formula. Thats it!
I guess there is even a possibility to make the formule able to track changes in more than one column and print only the column info which has been modified.
I tried with chatgpt but did not succeed. It tried to use attributes which do not exist in Grist.
are you using the paid version? Of ChatGPT?
Anyway, just tell it to find a solution without any external library besides standard python
No I have only the public version. I tried again but still not working.
I found a way… took me a LOT of conversation with ChatGPT, and I created the logic for it, it only gave me the code
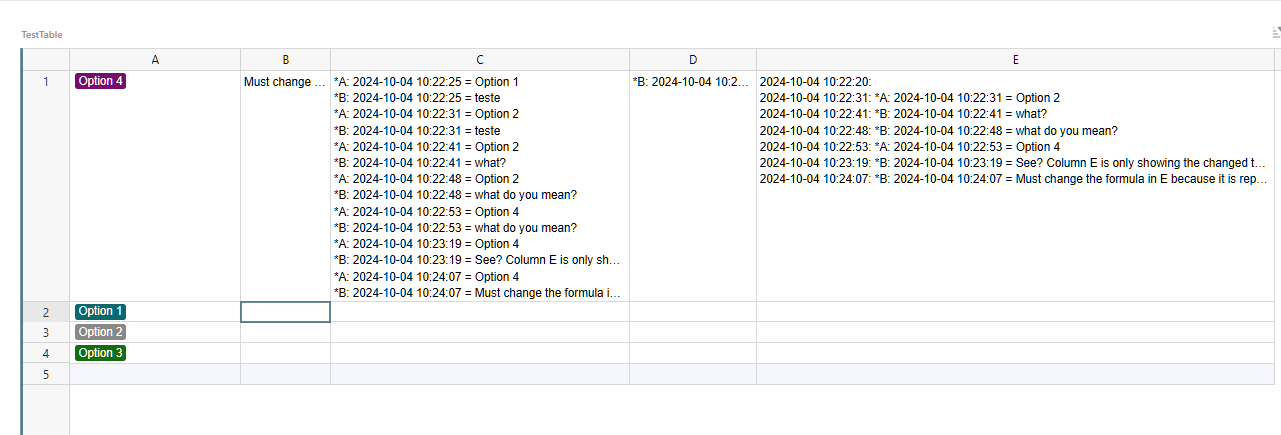
so, column C records changes in BOTH A and B
# Obter a hora atual no fuso horário configurado
current_time = NOW().strftime("%Y-%m-%d %H:%M:%S")
# Criar entradas separadas para as colunas A e B
new_entry_A = f"*A: {current_time} = { $A }"
new_entry_B = f"*B: {current_time} = { $B }"
# Combina as entradas com um separador de nova linha
new_entry = f"{new_entry_A}\n{new_entry_B}"
# Anexar as novas entradas ao valor existente, separadas por uma nova linha
return (value + "\n" + new_entry) if value else new_entry
column D captures the last 4 rows that start with * at column C. (if you wanted to monitor 3 columns, you would need 6 rows)
then it compares *A with *A, *B with *B and the one that changed, it keeps the changed row
# Separar os registros da coluna C em linhas
entries = $C.split("\n") if $C else []
# Filtrar apenas as entradas que começam com '*', ou seja, os novos registros
filtered_entries = [entry for entry in entries if entry.startswith("*")]
# Pegar os últimos 4 registros (2 para A e 2 para B)
last_entries = filtered_entries[-4:]
# Separar os registros de A e B
last_A_entries = [entry for entry in last_entries if entry.startswith("*A")]
last_B_entries = [entry for entry in last_entries if entry.startswith("*B")]
# Verificar se os dois últimos registros de A e B são iguais
if last_A_entries[-1].split(" = ")[1] == last_A_entries[-2].split(" = ")[1]:
# Se A for igual, ignorar
result_A = ""
else:
# Caso contrário, mostrar o último registro de A
result_A = last_A_entries[-1]
if last_B_entries[-1].split(" = ")[1] == last_B_entries[-2].split(" = ")[1]:
# Se B for igual, ignorar
result_B = ""
else:
# Caso contrário, mostrar o último registro de B
result_B = last_B_entries[-1]
# Mostrar o último registro de B se houver diferença, ou retornar uma string vazia
return "\n".join([result_A, result_B]).strip()
finally, column E works like the original formula… it records all changes in D (since D only shows ONE change at a time
# Obtém a hora atual no fuso horário configurado
current_time = NOW().strftime("%Y-%m-%d %H:%M:%S")
new_entry = f"{current_time}: { $D }"
return (value + "\n" + new_entry) if value else new_entry
1 Like
far from ideal. I mean… we needed 3 columns. One to capture ALL info, one to show only what changed, and one to record what changed.
One problem is that the column that captures all changes from 2 or more columns will grow very fast, since it also captures data that HAS NOT changed.
I don´t have a solution for that yet.
1 Like