Hey there!
I modified our prior example to include this: Community #1545
I created two examples for two different ways to do this. You can do this using Row ID or by using a Date column if you have one.
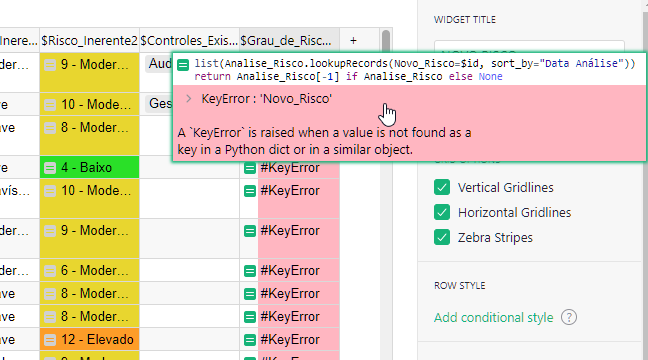
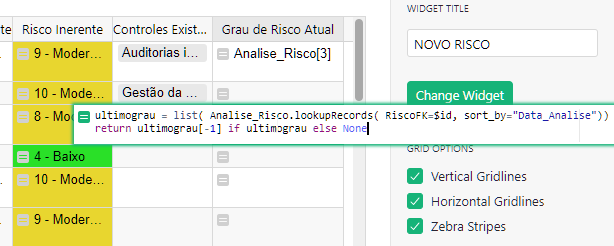
Row ID is a unique ID that is created when a new record is created. This will likely work fine for you but keep in mind that if you add a new record between existing records, that new record will be the ‘newest’ risk assessment. This would only cause a problem if you are going back to enter a prior one that may have been missed. As you see in the screenshot below, I added a new row between Row 1 and Row 3. Because ID 4 was next to be assigned, this row has ID 4 and therefore is the newest record so the Risk Degree for this record is returned at the top.
As long as you are entering the Risk data in order, then you won’t have any problems using Row ID but if you have a Date column, I would recommend using that as the date will always determine what is most recent  I’ll include both formulas below.
I’ll include both formulas below.
If using Row ID, the formula would be:
(Risk_Probability.lookupRecords().Risk_Degree_Text)[-1]
This makes a list of all records in the Risk Probability table then stores the value found in the ‘Risk Degree - Text’ column for each of those records. [-1] finds the last record in the list. Keep in mind that this list is created based on Row ID so the record with the highest ID will be returned, as you saw in the screenshot above.
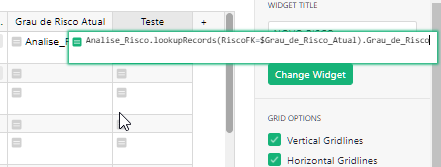
If using Date, the formula would be:
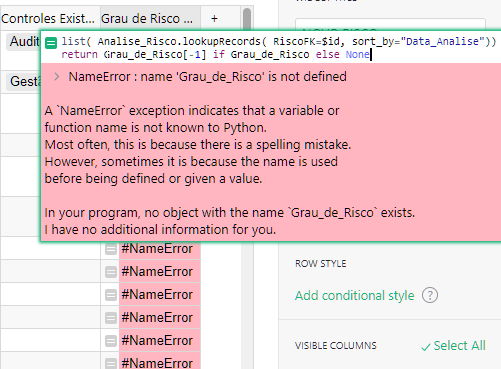
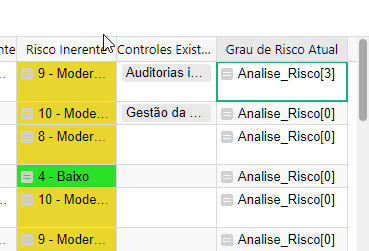
max_date = MAX(Risk_Probability.lookupRecords().Date)
return Risk_Probability.lookupRecords(Date=max_date).Risk_Degree_Text
First, we use LookupRecords to make a list of all records in the Risk Probability table. We pull the ‘Date’ value for each of those records using Dot Notation. MAX() finds the highest/most recent date in that list. we assign this date to the variable max_date.
Next, we use LookupRecords again to find the record in the Risk Probability table where the value in the Date column matches the date we found as our most recent date in the prior statement. Then, we use dot notation to return the value from the ‘Risk Degree Text’ column.
I hope this helps! Please let me know if you have any questions.
Thanks,
Natalie