Hi,
How to update all contents of a table from a local remote CSV file using Python API?
E.g. I have a remote table REMOTE_TABLE. Assuming I have a local CSV with the same headers as the REMOTE_TABLE, how to upload all the content of local CVS to the REMOTE_TABLE via Python API?
Here’s a possible script for Python3:
import requests
import pandas as pd
# Replace these with your values
API_KEY = 'YOUR_GRIST_API_KEY'
DOC_ID = 'YOUR_DOCUMENT_ID'
TABLE_NAME = 'REMOTE_TABLE'
CSV_FILE_PATH = 'PATH_TO_CSV_FILE'
df = pd.read_csv(CSV_FILE_PATH)
df = df.where(pd.notna(df), None) # replace NaNs with None
data_list = df.to_dict(orient='records')
# Set up the headers for the API request
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
# Endpoint URL for updating the table
url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/records'
# Upload new data from the CSV
grist_data = {"records": [{"fields": record} for record in data_list]}
response = requests.post(url, headers=headers, json=grist_data)
# Validate the response
if response.status_code != 200:
print("Failed to upload data")
print(response.json())
else:
print("Data uploaded successfully!")
This simply adds all the records, using this endpoint.
If you want to delete all the records first, I don’t think there is a simple endpoint (a good feature request?), but you can do it this way, inserting before the # Upload new data... line:
# Get all rowIds.
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise an error if the request failed
row_ids = [r["id"] for r in response.json()["records"]]
## Make a request to delete existing records (if you want to replace the table contents)
delete_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/data/delete'
response = requests.post(delete_url, headers=headers, json=row_ids)
response.raise_for_status() # Raise an error if the request failed
There are also some more powerful API endpoints e.g. add-or-update, to avoid adding duplicates.
Hi @Dmitry_Sagalovskiy and thank you for the starting script!
The problem is that I get this error: {'error': "Error manipulating data: [Sandbox] KeyError 'ΓΕΝΙΚΗ ΚΑΤΗΓΟΡΙΑ'"}.
So, my remote table has a column name in Greek language “ΓΕΝΙΚΗ ΚΑΤΗΓΟΡΙΑ” which means “General Category.” So I have some ideas from where this bug comes but still will need help!

- Does the API handle properly non-English column names in Grist, like Greek?
- Does the API handle properly empty cell values with something like:
df = df.where(pd.notna(df), None)?
- Does the API handle properly column names with 2-3-4 words length and spaces between those words like my case, where my column name has 2 words and 1 space between them:
ΓΕΝΙΚΗ ΚΑΤΗΓΟΡΙΑ?
- In the past, I had tried the Python API and especially the [update records](grist_api module — grist_api 0.1 documentation) function but I got something similar error like this:
{'error': "Error manipulating data: [Sandbox] KeyError 'ΓΕΝΙΚΗ ΚΑΤΗΓΟΡΙΑ'"} so I gave up…
Best
For the API, it is important to use Grist column IDs. If you click on a column header to select it, and click again to rename it, you’ll see two identifiers, like here:
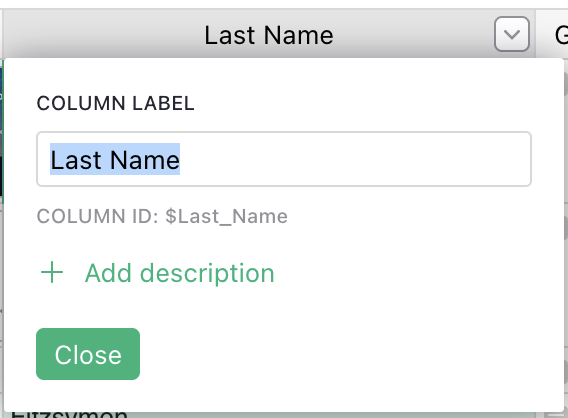
The first is the “column label” (here Last Name), and under it you’ll see the “column ID” (here, Last_Name, ignore the $ as that’s only needed for Grist formulas). The column ID is derived from the label but only uses English characters, and replaces punctuation with underscores.
Note that since your column labels use all non-English characters, the column ID would probably be something like “A”. (If you’d like, you can change the column ID in the creator panel.)
Once you switch your API calls to using column IDs, that should pretty much answer your other questions too.
Hello, again @Dmitry_Sagalovskiy !
How to switch my API calls to using column IDs using add records endpoint or add_or_update endpoint?
I apologize, that was a sloppy response. What I meant would make sense if you could update your CSV file to use column IDs in the headers instead of the labels. But that’s not a great plan, for one because column IDs aren’t meaningful when labels are non-English, and for another because Grist itself exports CSVs using labels!
So instead, we can update the script to translate the column identifiers from labels to IDs. This version will fetch all column IDs and labels, and will interpret CSV headers as labels (translating to ID for the API call). If a header is not a valid label, but is a valid ID, it will use that.
import requests
import pandas as pd
# Replace these with your values
API_KEY = 'YOUR_GRIST_API_KEY'
DOC_ID = 'YOUR_DOCUMENT_ID'
TABLE_NAME = 'REMOTE_TABLE'
CSV_FILE_PATH = 'PATH_TO_CSV_FILE'
df = pd.read_csv(CSV_FILE_PATH)
df = df.where(pd.notna(df), None) # replace NaNs with None
# Set up the headers for the API request
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
columns_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/columns'
response = requests.get(columns_url, headers=headers)
response.raise_for_status()
# Create a mapping from label to colRef (column ID)
columns_data = response.json()
column_mapping = {col["fields"]["label"]: col["id"] for col in columns_data["columns"]}
valid_column_ids = set(column_mapping.values())
new_columns = {
col: column_mapping.get(col) or col
for col in df.columns
if col in valid_column_ids or col in column_mapping
}
invalid_columns = set(df.columns) - set(new_columns.keys())
if invalid_columns:
print(f"Warning: Invalid column names skipped: {', '.join(invalid_columns)}")
df = df.drop(columns=invalid_columns)
df = df.rename(columns=new_columns)
data_list = df.to_dict(orient='records')
grist_data = [{"fields": record} for record in data_list]
# Endpoint URL for fetching/updating the table
url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/records'
# Get all rowIds.
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise an error if the request failed
row_ids = [r["id"] for r in response.json()["records"]]
## Make a request to delete existing records (if you want to replace the table contents)
delete_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/data/delete'
response = requests.post(delete_url, headers=headers, json=row_ids)
response.raise_for_status() # Raise an error if the request failed
# Validate the response
if response.status_code != 200:
print("Failed to delete existing records")
print(response.json())
exit()
# Upload new data from the CSV
response = requests.post(url, headers=headers, json={"records": grist_data})
# Validate the response
if response.status_code != 200:
print("Failed to upload data")
print(response.json())
else:
print("Data uploaded successfully!")
That worked @Dmitry_Sagalovskiy ! Thank you so much!
I only get this warning: Warning: Invalid column names skipped: **SOME GREEK TEXT**
Yes, I included that warning in the script: it shows names of columns in the CSV file that don’t match any columns in the destination Grist table.
1 Like
Hi @Dmitry_Sagalovskiy ! I have a csv with 3480 rows of data, 9 MB. I can upload easily this file via Grist admin area but using this script with API I cannot upload the csv. Here is the error I get:
Failed to upload data
{'error': 'request entity too large'}
Yes, an individual API request is limited to 1MB, I believe. Here’s a version that batches add-record requests to keep them within the limit:
import json
import os
import requests
import pandas as pd
# Replace these with your values
API_KEY = 'YOUR_GRIST_API_KEY'
DOC_ID = 'YOUR_DOCUMENT_ID'
TABLE_NAME = 'REMOTE_TABLE'
CSV_FILE_PATH = 'PATH_TO_CSV_FILE'
df = pd.read_csv(CSV_FILE_PATH)
df = df.where(pd.notna(df), None) # replace NaNs with None
# Set up the headers for the API request
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
columns_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/columns'
response = requests.get(columns_url, headers=headers)
response.raise_for_status()
# Create a mapping from label to colRef (column ID)
columns_data = response.json()
column_mapping = {col["fields"]["label"]: col["id"] for col in columns_data["columns"]}
valid_column_ids = set(column_mapping.values())
new_columns = {
col: col if col in valid_column_ids else column_mapping[col]
for col in df.columns
if col in valid_column_ids or col in column_mapping
}
invalid_columns = set(df.columns) - set(new_columns.keys())
if invalid_columns:
print(f"Warning: Invalid column names skipped: {', '.join(invalid_columns)}")
df = df.drop(columns=invalid_columns)
df = df.rename(columns=new_columns)
data_list = df.to_dict(orient='records')
grist_data = [{"fields": record} for record in data_list]
# Endpoint URL for fetching/updating the table
url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/records'
# Get all rowIds.
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise an error if the request failed
row_ids = [r["id"] for r in response.json()["records"]]
## Make a request to delete existing records (if you want to replace the table contents)
delete_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/data/delete'
response = requests.post(delete_url, headers=headers, json=row_ids)
response.raise_for_status() # Raise an error if the request failed
# Validate the response
if response.status_code != 200:
print("Failed to delete existing records")
print(response.json())
exit()
def get_size_in_bytes(data):
serialized = json.dumps(data, ensure_ascii=False)
return len(serialized.encode('utf-8'))
def batched_requests_by_size(data, max_bytes=1_000_000):
batch = []
current_size = 0
for row in data:
row_size = get_size_in_bytes(row)
if (current_size + row_size) > max_bytes:
yield batch
batch = []
current_size = 0
batch.append(row)
current_size += row_size
if batch:
yield batch
# Upload new data from the CSV in batches
for batch in batched_requests_by_size(grist_data):
print(f"Adding {len(batch)} records")
response = requests.post(url, headers=headers, json={"records": batch})
response.raise_for_status()
print("Data uploaded successfully!")
Sorry, @Dmitry_Sagalovskiy, the script does not work. So, I reduced the MAX_BYTES = 500_000 but I still does not work.
Here is the script:
import json
import os
import requests
import pandas as pd
# Constants
API_KEY = 'YOUR_GRIST_API_KEY'
DOC_ID = 'YOUR_DOCUMENT_ID'
TABLE_NAME = 'REMOTE_TABLE'
CSV_FILE_PATH = 'PATH_TO_CSV_FILE'
MAX_BYTES = 500_000 # Reduced from 1_000_000 to 500_000
# Function to calculate size of data in bytes
def calculate_size_in_bytes(data):
serialized = json.dumps(data, ensure_ascii=False)
return len(serialized.encode('utf-8'))
# Function to create batches of requests by size
def create_batched_requests_by_size(data, max_bytes):
batch = []
current_size = 0
for row in data:
row_size = calculate_size_in_bytes(row)
if (current_size + row_size) > max_bytes:
yield batch
batch = []
current_size = 0
batch.append(row)
current_size += row_size
if batch:
yield batch
# Load and clean data
df = pd.read_csv(CSV_FILE_PATH)
df = df.where(pd.notna(df), None) # replace NaNs with None
# Set up the headers for the API request
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
# Fetch column data from API
columns_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/columns'
response = requests.get(columns_url, headers=headers)
response.raise_for_status()
# Create a mapping from label to colRef (column ID)
columns_data = response.json()
column_mapping = {col["fields"]["label"]: col["id"] for col in columns_data["columns"]}
# Validate and rename columns
df = df.rename(columns=column_mapping)
data_list = df.to_dict(orient='records')
grist_data = [{"fields": record} for record in data_list]
# Endpoint URL for fetching/updating the table
url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/records'
# Get all rowIds and delete existing records
response = requests.get(url, headers=headers)
response.raise_for_status()
row_ids = [r["id"] for r in response.json()["records"]]
delete_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/data/delete'
response = requests.post(delete_url, headers=headers, json=row_ids)
response.raise_for_status()
# Validate the response
if response.status_code != 200:
print("Failed to delete existing records")
print(response.json())
exit()
# Upload new data from the CSV in batches
for batch in create_batched_requests_by_size(grist_data, MAX_BYTES):
print(f"Adding {len(batch)} records")
response = requests.post(url, headers=headers, json={"records": batch})
response.raise_for_status()
print("Data uploaded successfully!")
The problem is that I get this error:
Adding 148 records
Traceback (most recent call last):
File "MYSCRIPT.py", line 86, in <module>
response.raise_for_status()
File "/usr/lib/python3/dist-packages/requests/models.py", line 940, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://api.getgrist.com/api/docs/DOC_ID/tables/TABLE_NAME/records
Hmm, this is hard to debug without the error details. You can add this method:
def handle_response(response):
try:
response.raise_for_status()
return response
except requests.HTTPError as e:
try:
# Try extracting a more descriptive error message
error_message = response.json()["error"]
raise requests.HTTPError(f"{e.response.status_code}: {error_message}")
except (ValueError, KeyError):
# If there's any issue, re-raise the original error
raise e
And replace code like
response = requests.post(...)
response.raise_for_status()
with one line
response = handle_response(requests.posts(...))
And it will produce more informative errors.
@Dmitry_Sagalovskiy there were 2 problems.
a) Pandas re-created NaN values after the data_list = df.to_dict(orient='records') so the JSON data were wrong
b) My local csv file contained some columns that those columns did not exist on the remote table.
So, I fixed those 2 bugs, refactored the code and finally I made a script that works and I want to share my solution with the Grist community:
This code is used to upload data from a CSV file to a Grist table. It first loads the data from the CSV file, cleans it, and then uploads it to the Grist table in batches. The data is uploaded in batches to avoid exceeding the maximum byte size that can be sent in one request. The response from each API request is handled and any errors are raised.
My working script:
import json
import os
import requests
import pandas as pd
import math
# Constants
API_KEY = 'YOUR_GRIST_API_KEY'
DOC_ID = 'YOUR_DOCUMENT_ID'
TABLE_NAME = 'REMOTE_TABLE'
CSV_FILE_PATH = 'PATH_TO_CSV_FILE'
MAX_BYTES = 500_000 # Maximum bytes that can be sent in one request
# Headers for API request
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
def calculate_size_in_bytes(data):
"""
Function to calculate the size of the data in bytes.
Args:
data : The data whose size is to be calculated.
Returns:
The size of the data in bytes.
"""
serialized = json.dumps(data, ensure_ascii=False)
return len(serialized.encode('utf-8'))
def create_batched_requests_by_size(data, max_bytes):
"""
Function to create batches of data that do not exceed the maximum byte size.
Args:
data : The data to be batched.
max_bytes : The maximum byte size of a batch.
Yields:
The next batch of data.
"""
batch = []
current_size = 0
for row in data:
row_size = calculate_size_in_bytes(row)
if (current_size + row_size) > max_bytes:
yield batch
batch = []
current_size = 0
batch.append(row)
current_size += row_size
if batch:
yield batch
def handle_response(response):
"""
Function to handle the response from the API request.
Args:
response : The response from the API request.
Returns:
The response if the request was successful.
Raises:
HTTPError : If the request was not successful.
"""
try:
response.raise_for_status()
return response
except requests.HTTPError as e:
try:
error_message = response.json()["error"]
print("\n\nERROR MESSAGE: ", error_message)
raise requests.HTTPError(f"{e.response.status_code}: {error_message}")
except (ValueError, KeyError):
raise e
# Load and clean data
df = pd.read_csv(CSV_FILE_PATH) # Load data from CSV file
df = df.where(pd.notna(df), None) # Replace NaN values with None
with requests.Session() as session: # Using requests.Session for multiple requests
session.headers.update(headers) # Update session headers
# Fetch column data from API
columns_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/columns'
response = handle_response(session.get(columns_url)) # Handle response
# Create a mapping from label to colRef (column ID)
columns_data = response.json()
column_mapping = {col["fields"]["label"]: col["id"] for col in columns_data["columns"]}
# Check if all columns in dataframe exist in Grist table
for col in df.columns:
if col not in column_mapping.keys():
print(f"Column '{col}' does not exist in Grist table. Removing it from dataframe.")
df = df.drop(columns=[col]) # Remove non-existent columns
# Rename columns
df = df.rename(columns=column_mapping)
data_list = df.to_dict(orient='records') # Convert dataframe to list of dictionaries
# Convert NaN values to None after converting to dictionary - AGAIN!
for record in data_list:
for key, value in record.items():
if isinstance(value, float) and math.isnan(value):
record[key] = None # Replace NaN values with None
grist_data = [{"fields": record} for record in data_list] # Prepare data for Grist
# Endpoint URL for fetching/updating the table
url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/records'
# Get all rowIds and delete existing records
response = handle_response(session.get(url)) # Handle response
row_ids = [r["id"] for r in response.json()["records"]] # Get row ids
delete_url = f'https://api.getgrist.com/api/docs/{DOC_ID}/tables/{TABLE_NAME}/data/delete'
response = handle_response(session.post(delete_url, json=row_ids)) # Delete existing records
# Validate the response
if response.status_code != 200:
print("Failed to delete existing records")
print(response.json())
exit()
# Upload new data from the CSV in batches
for batch in create_batched_requests_by_size(grist_data, MAX_BYTES):
print(f"Adding {len(batch)} records")
response = handle_response(session.post(url, json={"records": batch})) # Upload data
print("Data uploaded successfully!")
Best
5 Likes
Hello,
I have to update small tables with csv files which are incrementing one line after the other.
While the script above would permit this will not be able to merge lines.
I tried the import function from document and it works well, given the possibility to merge line with same timestamp avoid duplication and easy update.
So my question is, is there anyway to autmate the grist csv importer ?
1 Like