I am learning Grist by attempting to implement an Excel-based application with a substantial amount of VBA code, forms and about half a dozen tables. The tables are stored one per sheet. The VBA code implements a subset of SQL-like expressions to be able to select, filter, etc. For example, I can:
“SELECT field1, field2, field n FROM table_name WHERE some_field = some_value ORDERBY something”
The tables have primary keys used as foreign keys to setup the relational model.
All user interaction is through VBA forms. In other words, no direct editing or viewing of tables at all.
I should add that I was going to re-implement the application using Python/Django due to a need to be able to have multiple users, permissions, etc. The application has outlived what is reasonable using Excel. That’s when I learned about Grist. It seems like a potentially good path. Just trying to understand it at this point.
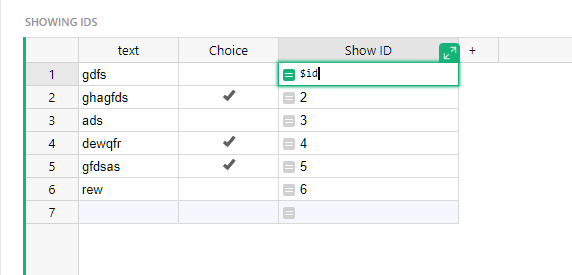
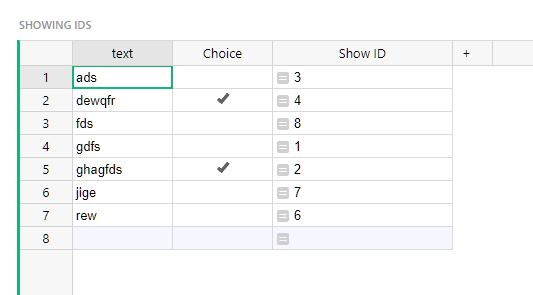
I imported all tables into Grist. The first discovery is that my “ID” PK columns don’t seem to have a way to be set to auto-increment and remain unique. I did find a couple of threads on the subject, this being one of them:
A UUID can serve well as a PK, however, I already have a PK column in every table and FK references to these PK’s in various tables. Other than a tedious manual task, not sure how I would create a UUID based PK field on every table and then edit/modify/add the corresponding FK’s on the tables that need to reference them. While I understand UUID/GUID’s, there’s a simplicity to small sequential numbers when it comes to having to manually deal with references.
Do I need to export the table with UUID PK’s in to Excel, use tools there to mend the FK references and then re-import the data into Grist?
In the various examples I have seen, I don’t recall seeing traditional PK/FK auto-increment fields used at all. Is this the Grist philosophy? How should I think of this?
I am going through tutorials and have watched a few videos. I haven’t found a detailed treatment of how to think about Grist in traditional DBMS terms. I’m sure it’s out there.
Thanks.