Prompted by a question from @dmitry-grist:
Can I ask which service you used to generate PDFs from Grist data? I feel this wish comes up fairly often, so I’m interested in recommendations!
Here goes one possible solution. I am using the Invoicing template as a basis modified to generate the PDF using an external service and save it onto Grist.
Resources:
- Grist Document, this is the base template with modifications.
- Pipedream.com account, affiliate link.
- APITemplate.io account, affiliate link.
How does it work
- We collect all relevant record data and submit it to a Webhook in Pipedream,
- Pipedream unpacks the data and:
a. Submits to APITemplate.io for rendering
b. Uploads the PDF file to Grist
c. Redirects the request to the PDF file. - Any change to a relevant column will wipe the PDF thus triggering new rendering next. (see caveats below).
- Deleting the PDF will have the same effect.
You can see the whole pipedream workflow here
more
It is important to save the rendered PDF to not re-render every time (pay per use and such).
This should work with any other workflow engine (Zapier, etc) that can handle arbitrary code and webhooks. I just like Pipedreams “code first” approach.
Should work with any API that renders PDF. APITemplate has a WYSIWYG editor, which is nice sometimes.
Implementation details
Collect and Submit
Collect and submit
We use a URL field that will either output the URL to the stored PDF or link to the webhook to request a rendering of a PDF.
If we have $PDFId (aka, an attachment) shortcircuit and link tothat, otherwise:
- We must use GET, which means all data must be in the URL.
- URLs shall not exceed 2000 characters, so we will compress the data
- URLs must be quoted, we do base64 encoding
So we basicaly use RECORD() to get the data, json.dumps with an handler for non basic types to get JSON, then zlib + base64 to prepare the URL.
This is the Formula on the OpenPDF column:
from records import Record
import json
import zlib
from urllib.parse import quote_plus
from base64 import b64encode
if $PDFId:
return f"https://docs.getgrist.com/api/docs/k54r5rMdBhjnDEpqdejAdk/attachments/{$PDFId}/download"
def encode_complex(value):
dtype = type(value)
if issubclass(dtype, Record):
# This should be the end of the `expand_refs` chain.
return None
elif dtype in [date, datetime]:
return value.isoformat()
else:
return (field, value)
d = RECORD(rec, expand_refs=1, dates_as_iso=True)
js =json.dumps(d, default=encode_complex)
b = bytes(js, 'utf-8')
cdata = zlib.compress(b, 9) # URLs longer than 2000 characters... bad news. So we compress.
data = b64encode(cdata)
return "https://eotfnn8f3bvzay5.m.pipedream.net/new-pdf?data=" + quote_plus(data)
Orchestration
Orchestration
This is where the sauce gets made, in Pipedream.
A web trigger (“trigger”) gets the data via GET URL:
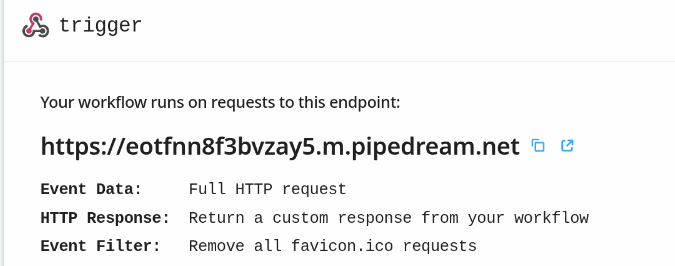
A Python block (“parse_data”) decodes the data from the URL:
import json
import zlib
from urllib.parse import unquote
from base64 import b64decode
def handler(pd: "pipedream"):
b = pd.steps["trigger"]["event"]["query"]["data"]
data = json.loads(zlib.decompress(b64decode(unquote(b))))
number = data['Number']
data.update({'filename': f"Invoice-{number}.pdf"})
return {"data": data}
A call to APITemplate.io renders the PDF
Pay attention to “Data” where we pass in the data decoded from the python block above.
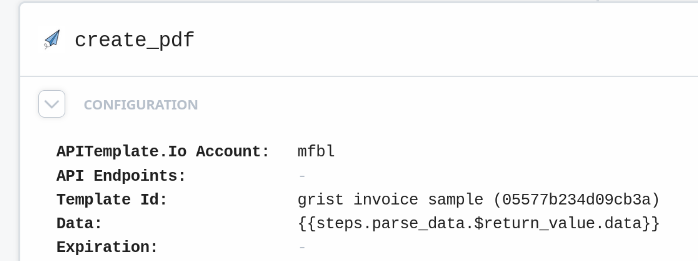
We use a Bash block (“download_pdf”) with curl to get the rendered PDF
set -e
DOWNLOAD_URL=`cat $PIPEDREAM_STEPS | jq -r '.create_pdf."$return_value".download_url'`
FILENAME=`cat $PIPEDREAM_STEPS | jq -r '.parse_data."$return_value".data.filename'`
echo "Downloading to /tmp/$FILENAME from $DOWNLOAD_URL"
curl -sL --output /tmp/$FILENAME $DOWNLOAD_URL
echo "{path: $FILENAME}" >> $PIPEDREAM_EXPORTS
We use Python ("upload_to_grist) to upload the data to Grist
(Pipedream does not support the attachment endpoint).
import requests
doc_id = "k54r5rMdBhjnDEpqdejAdk"
table_id = "Prepare_Invoices"
def handler(pd: "pipedream"):
filename = "/tmp/" + pd.steps["parse_data"]["$return_value"]["data"]["filename"]
record_id = pd.steps["parse_data"]["$return_value"]["data"]["id"]
print(f"Uploading {filename} to {table_id}.{record_id} of {doc_id}")
token = f'{pd.inputs["grist"]["$auth"]["api_key"]}'
authorization = f'Bearer {token}'
headers = {"Authorization": authorization}
response = requests.post(
f"https://docs.getgrist.com/api/docs/{doc_id}/attachments",
files={"upload": open(filename, "rb")},
headers=headers,
)
assert response.status_code == 200, response.json()
attachment_id = response.json()[0]
cell_value = ["L", attachment_id]
response = requests.patch(
f"https://docs.getgrist.com/api/docs/{doc_id}/tables/{table_id}/records",
json={"records": [{"id": record_id,
"fields": {"PDF": ["L", attachment_id]}}]},
headers=headers,
)
assert response.status_code == 200, response.json()
return f"{attachment_id: {attachment_id}}"
We use the return_http_response block to redirect the user
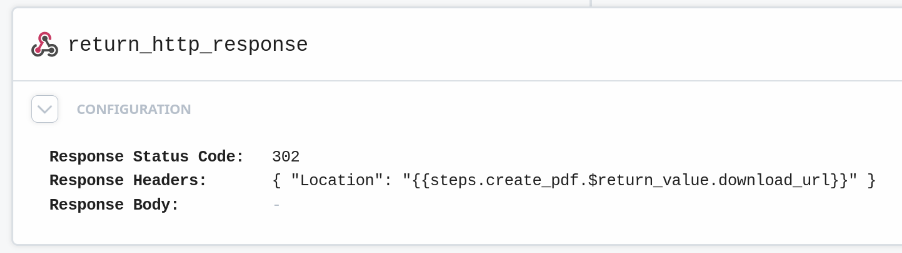
Other details in the Grist Document
PDFcolumn has a trigger formula to drop it when certain fields are changed.PDFIdis needed for the Viewer widget,PDFNameis useful to show some useful title in the Viewer.
Notes and caveats
- The Pipedream workflow could be much shorter if you just call for the PDF and return it, half of the workflow is to save back the file to Grist for future reference.
- Trigger formulas do not trigger on changes to the contents of References, only to the list of those. Thus, changing an Item does not trigger a PDF removal (this merits a different post on workarounds)
- This is running on my own account so you might hit API limits when testing.
- For visualizing the PDF I used @TomNit 's widget based on ViewerJS.
- This is just an example on how to leverage two services to generate highly customized PDF and/or images from Grist